A continuación se hará una breve descripción de distintas aplicaciones Free/Open Source para editar PDFs aplicadas a distintas tareas, así como su instalación y ejemplos de uso. Es importante indicar que las pruebas se han realizado sobre una máquina con Windows 10, pero el funcionamiento de las aplicaciones es exactamente el mismo en GNU/Linux. Como podéis ver, el PDF utilizado para las pruebas es un simple manual de instrucciones de un microondas, con páginas en formato A4 y con páginas en vertical y horizontal.
La primera parte de este tutorial explica cómo instalar las herramientas, mientras que el resto están dedicadas a operaciones específicas: editar texto y contenido del pdf, ordenas y combinar páginas, bloquear y comprimir PDFs, y por último extraer texto a partir de imagen.
- Instalación de programas
- Editar contenido
- Editar páginas
- Bloquear PDFs
- Comprimir PDF
- OCR (Reconocimiento Óptico de Caracteres)
Instalación de Programas
LibreOffice Draw
Para empezar, presentamos LibreOffice Draw, del propio paquete LibreOffice. En principio, es un editor de gráficos vectoriales, pero resulta que para la edición de PDFs es de las mejores opciones de la siguiente lista. A continuación detallamos cómo se realiza la instalación de la aplicación.
WINDOWS: Para instalarlo en el Sistema Operativo de Windows accederemos al siguiente enlace https://es.libreoffice.org/descarga/libreoffice/ que nos lleva a la página de descarga del paquete LibreOffice, que tiene el siguiente aspecto.
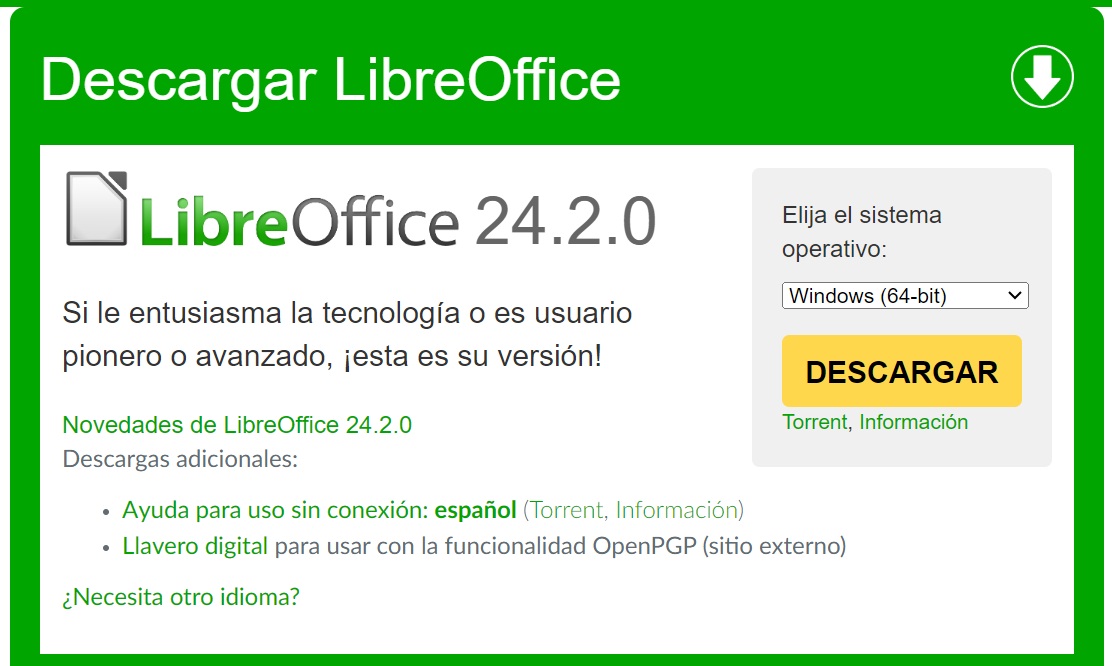
Elegiremos Windows (64-bit), que es la opción ya predefinida. Con esto, descargaremos el instalador del paquete LibreOffice. Una vez ejecutado el instalador deberemos seleccionar nuestras preferencias, como la ruta donde se ubica el paquete, entre otros. Cuando finalice, dentro de todos los editores instalados, elegiremos el de LibreOffice Draw y comprobaremos que se ha instalado correctamente.
LINUX: En el Sistema Operativo Linux existen varias maneras de hacerlo. Si usamos una distribución basada en Debian (como Ubuntu) deberemos de acceder a la terminal y escribir el siguiente comando: sudo apt install libreoffice .
Una vez tengamos el paquete instalado y funcionando correctamente, abriremos el PDF a editar. Podemos abrirlo desde el propio LibreOffice Draw en Archivo -> Abrir o desde el explorador de archivos con un click derecho sobre el PDF y en la sección Abrir con > elegiremos LibreOffice Draw. Una vez abierto nos debe de aparecer la siguiente pantalla.
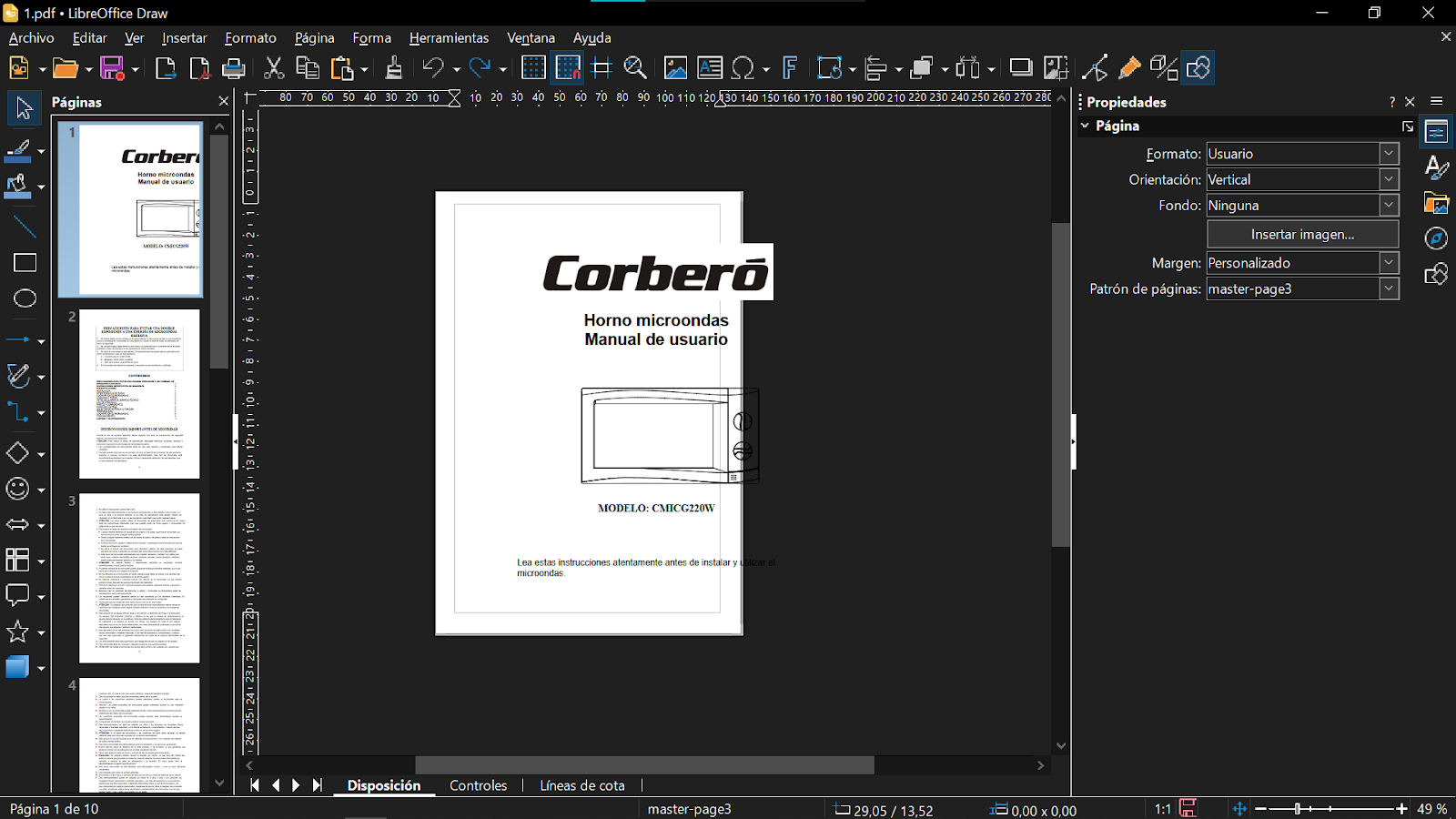
Vemos que el formato en un principio no coincide, ya que es la primera vez que abrimos Libreoffice Draw, por lo que debemos fijarnos que en la parte derecha de la pantalla, donde nos aparece la sección Propiedades y en Formato, aparece Usuario, una configuración prestablecida. Si abrimos el desplegable ya nos aparecen todos los tamaños estándar que soporta. En mi caso elegiré formato A4.
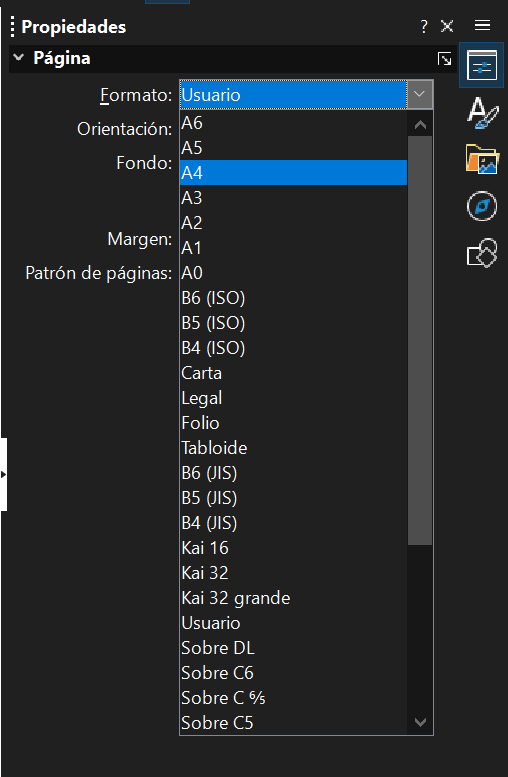
Ahora sí nos aparecerán las páginas en su formato correcto, y, por tanto, podemos empezar a editar el PDF correctamente.
Una vez se haya editado el PDF, la aplicación ofrece un atajo directamente para exportarlo como PDF, aunque también da la opción a exportar en otros formatos. En el siguiente vídeo se muestra este atajo para exportar como PDF, donde indicamos la ruta de destino, el nombre final del archivo y pulsando la tecla Intro lo guardaremos.
PDF Arranger
PDF Arranger es otra aplicación Open Source, aunque más limitada que la anterior, ya que ahora solo podremos editar el orden de las páginas, no el contenido de ellas. Con PDF Arranger podemos tanto eliminar como añadir páginas a nuestro gusto, de igual forma que en LibreOffice Draw, salvo que ahora tenemos una interfaz gráfica más sencilla e intuitiva. De igual forma, también podremos combinar páginas de otros archivos PDF en uno.
A continuación detallamos el proceso de instalación para cada Sistema Operativo.
WINDOWS: Accederemos al siguiente enlace https://github.com/pdfarranger/pdfarranger donde encontramos el repositorio de github de este proyecto. Si nos desplazamos un poco hacia abajo en la página, además de diferente documentación, encontramos los accesos directos para instalar la aplicación.

LINUX: Dado que es un repositorio de github, podemos clonarlo en nuestra máquina Linux para trabajar con él. Toda la información para ello se detalla en el enlace al repositorio. Para realizar una instalación normal del programa bastará con ejecutar en la terminal el siguiente comando (si usamos distribución basada en Debian): sudo apt install pdfarranger. En mi caso, estoy trabajando en un Ubuntu 22.04 y podemos ver que la versión instalada es la correcta, y concuerda según se menciona en el repositorio.
En mi caso elegiré la instalación con la versión para Windows, donde se me descargará un instalador, el cual hay que ejecutar y posteriormente configurar la propia instalación según nuestras preferencias. Una vez instalado lo abriremos y nos debe de aparecer una pantalla como la siguiente.
Tal y como mencioné anteriormente, es una interfaz minimalista, donde podremos abrir los PDFs a editar desde el botón de la esquina superior izquierda.
Scribus
Esta última aplicación quizá sea la menos versátil de las tres presentadas, pero aún así puede ser útil según las necesidades. Con esta aplicación podremos editar el contenido de las propias páginas, pero no el texto, por lo que tan solo podremos modificar la posición tanto de las imágenes, objetos y cuadros de texto. Sí que podremos añadir cuadros de texto nuevos y, además, podremos eliminar páginas, pero no añadirlas de otros PDFs. A continuación se detalla la instalación de esta aplicación para cada Sistema Operativo.
WINDOWS: Debemos acceder a la página, mediante el siguiente enlace https://www.scribus.net/downloads/ donde encontramos el instalador para descargar, según qué Sistema Operativo utilicemos. Seleccionamos el instalador para Windows 10 (no está disponible para W11), se nos descargará, y lo ejecutaremos y configuraremos según nuestras necesidades.
LINUX: Para Linux podemos tanto descargarnos el instalador desde el enlace anterior, como hacerlo desde la terminal. Con la segunda opción debemos de escribir el siguiente comando: sudo apt install scribus .
Una vez instalado correctamente, al abrirlo nos aparecerá la siguiente interfaz.
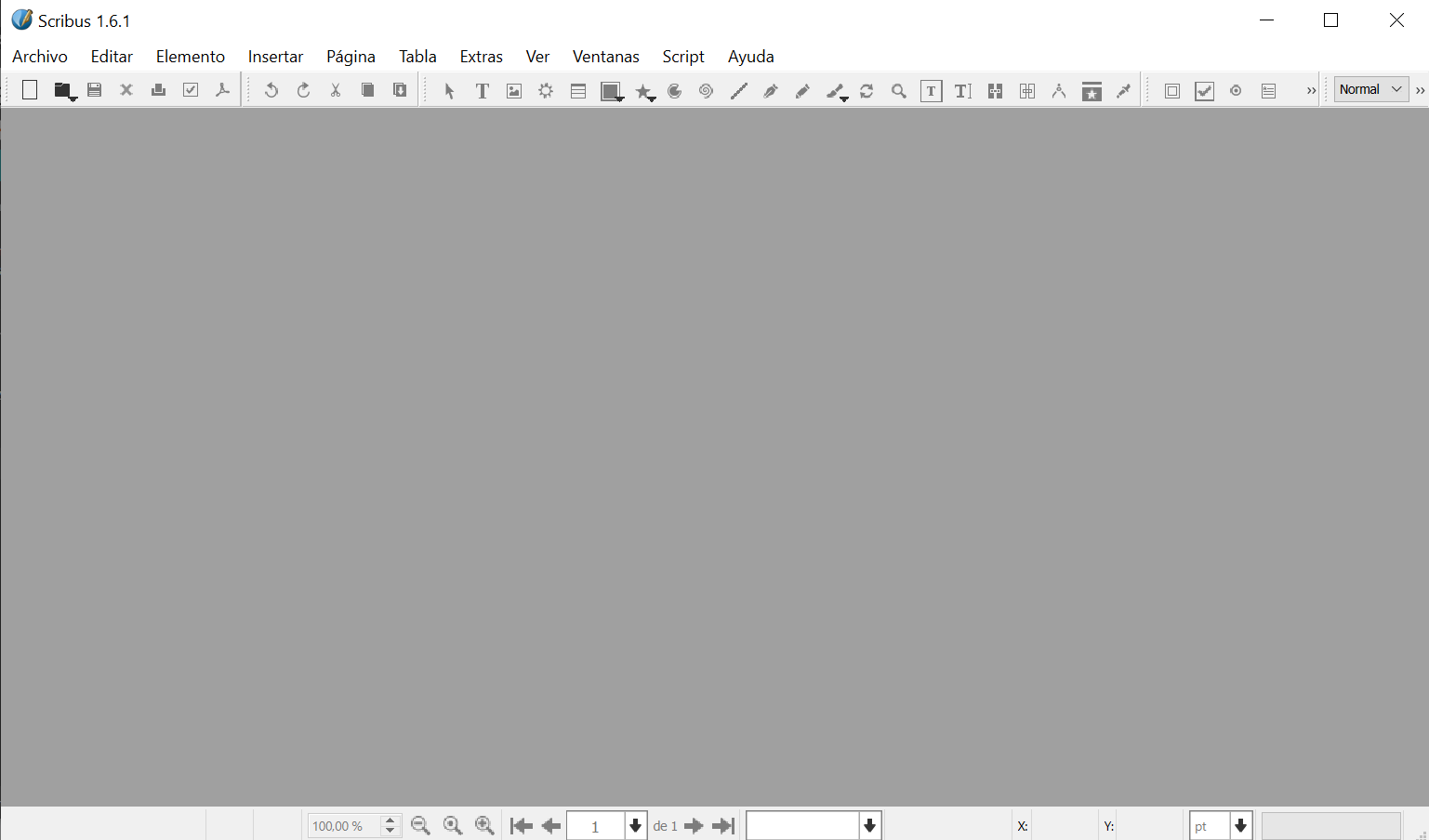
Para abrir el PDF a editar debemos de dirigirnos a Archivo -> Abrir y tendremos que indicar la ruta del archivo.
Una vez seleccionado el archivo a editar nos aparecerá el siguiente menú.
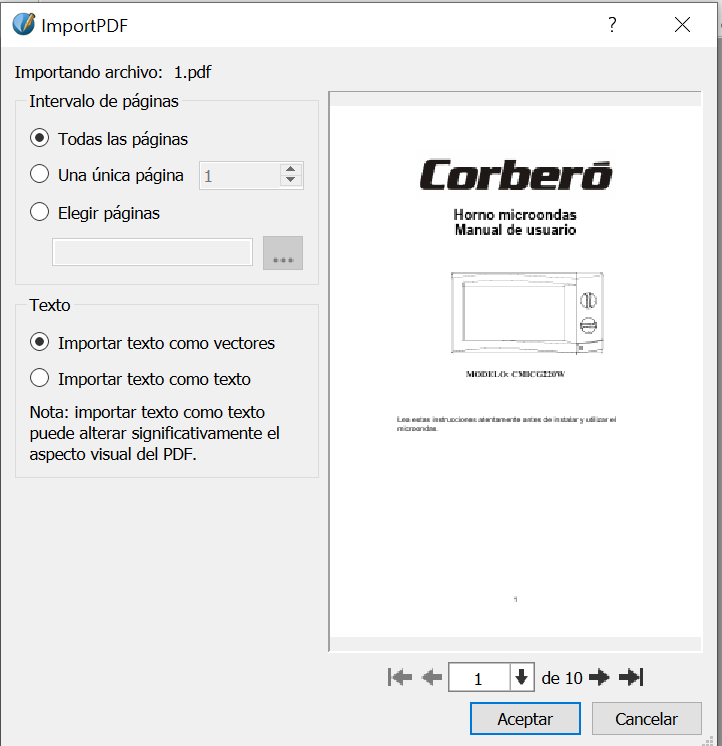
Podemos ver que, a pesar que nos da la opción de que el texto aparezca como texto, y no como vectores, pero si lo hacemos el PDF quedará realmente alterado, y aún así tampoco podremos editar el propio texto. Una vez editado, podremos guardarlo directamente como un PDF nuevo con el botón que está directamente indicado para ello, arriba a la izquierda.
Se puede observar que incluso exportando como nuevo PDF el propio archivo, sin haberlo alterado, saltan algunos errores a la hora de exportarlo con este programa. Además, tal y como comenté al principio, este PDF contiene páginas en vertical y horizontal, y Scribus no interpreta bien las páginas en horizontal, como vamos a ver a continuación. Altera la orientación del contenido, y reduce su tamaño de tal forma que el texto queda inteligible.

Tesseract OCR
Muchas veces podemos encontrar con que tenemos un PDF que se creó a partir de imagen, por lo que en principio con las herramientas anteriores no podríamos editar su contenido. Para ello, nacen las herramientas OCR, Optical Character Recognition o Reconocimiento Óptico de Caracteres en español. Gracias a un OCR podemos ser capaces de, a partir de una imagen, obtener el texto que contiene en ella.
Pues bien, por parte de Google, encontramos la herramienta libre Tesseract OCR la cual se encuentra disponible, con código abierto, para macOS, Windows y GNU/Linux. Toda la información se encuentra disponible en el repositorio del siguiente enlace https://github.com/UB-Mannheim/tesseract/wiki. Previamente, mencionar que esta aplicación funciona mediante comandos en la terminal. Son comandos sencillos, pero si lo prefieres, gImageReader, la siguiente aplicación, realiza lo mismo mediante una interza gráfica, y su motor está basado en Tesseract OCR, por lo que requiere también su instalación previa. A continuación explicaremos el proceso de instalación de Tesseract OCR.
WINDOWS: Para instalarlo en el Sistema Operativo de Windows accederemos al anterior enlace, y en el repositorio encontraremos el instalador directamente, junto a otros archivos de documentación. Pinchando sobre el .exe que aparece automáticamente se descargará el ejecutable del instalador.
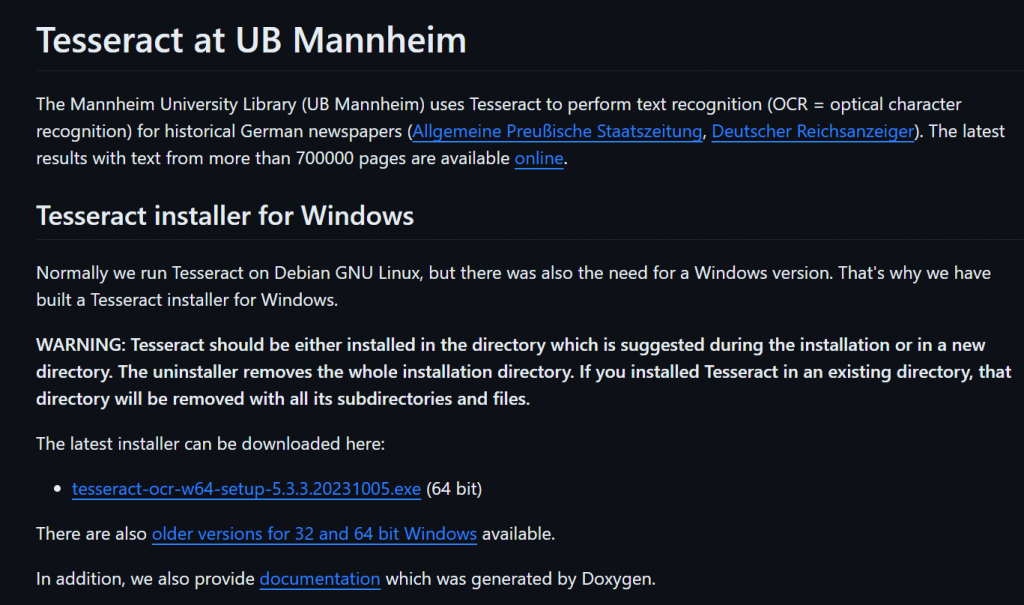
Una vez ejecutado el instalador deberemos seleccionar nuestras preferencias, como elegir una instalación completa (recomendada), la ruta donde se ubican los archivos de programa, entre otros. Cuando finalice, deberemos de obtener la ruta del ejecutable de la aplicación. Si hemos dejado la ruta por defecto en la instalación, esta será la ruta: C:\Program Files\Tesseract-OCR\tesseract.exe.
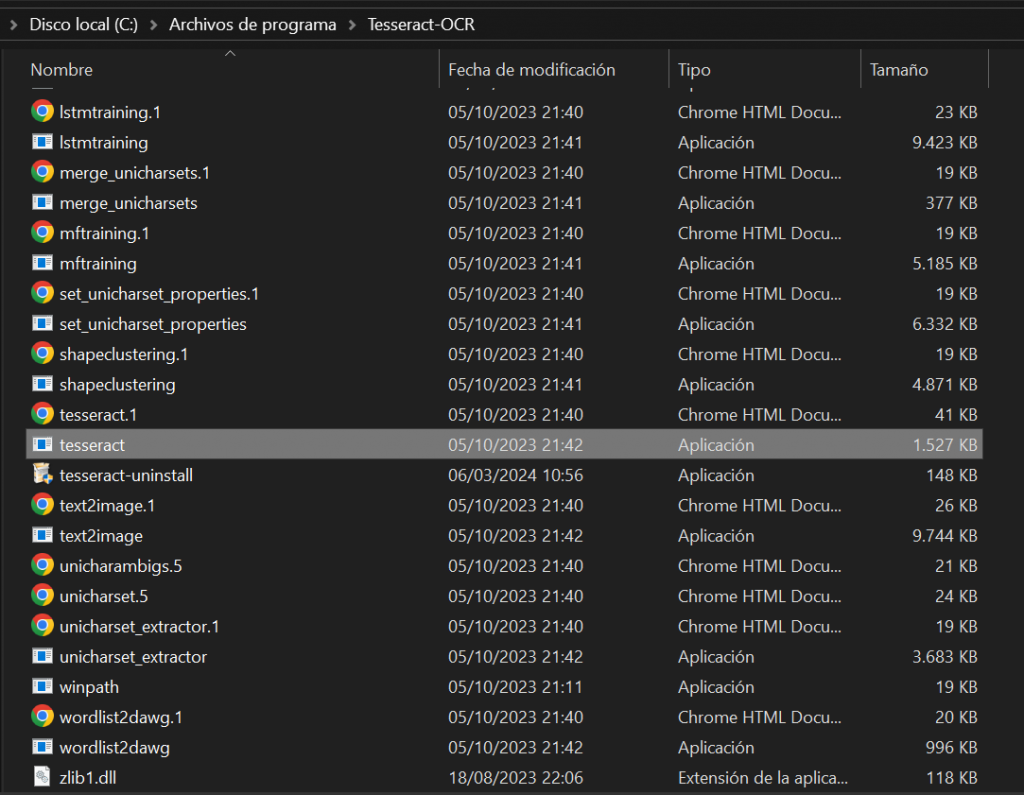
Deberemos de copiar esa ruta y ahora, en el buscador de Windows accederemos a Editar las variables de entorno del sistema.
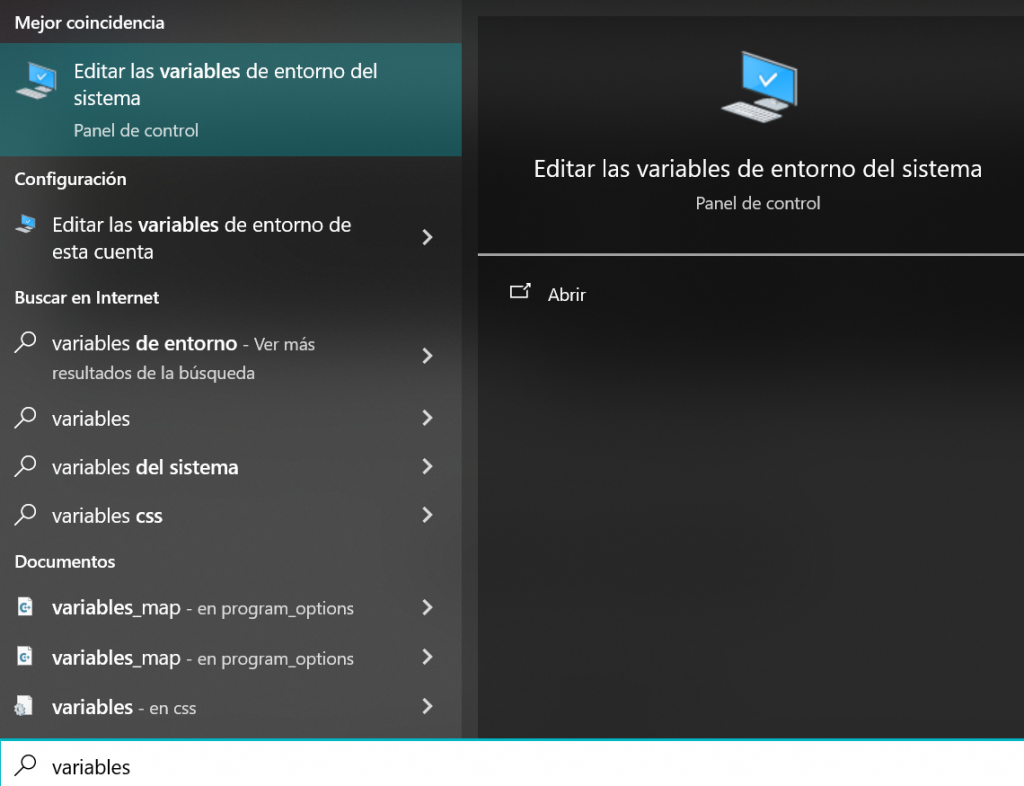
Una vez dentro, nos dirigiremos a Opciones avanzadas -> Variables de entorno y obtendremos las variables de entorno del usuario en el que nos encontremos. Debemos hacer click sobre Path para acceder al editor de variables de entorno y debemos añadir una nueva ruta, que será la mencionada anteriormente.
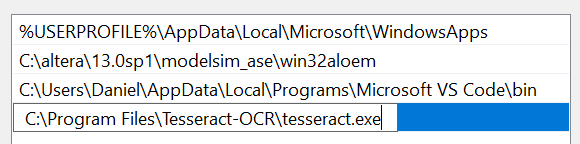
Para cerrar todas las pestañas abiertas deberemos de pulsar en el botón Aceptar en cada una de ellas. Llegados a este punto, los más técnicos podrán usarlo mediante terminal de comandos, explicado a detalle en el repositorio. En resumen, si la instalación ha sido correcta con el siguiente comando sería suficiente tesseract ruta_de_imagen ruta_de_archivo_de_salida. En la sección 6 se explicará a detalle gImageReader, ya que es el que a más público llegará.
LINUX: Para distribuciones GNU/Linux, como Ubuntu, debemos de abrir una terminal y escribir el siguiente comando: sudo apt install tesseract-ocr. Con esto ya lo tenemos instalado en el sistema.
gImageReader
Por otro lado, si prefieres utilizar una interfaz gráfica más visual, puedes visitar el repositorio de https://github.com/manisandro/gImageReader. gImageReader es una interfaz gráfica destinada para el motor de Tesseract OCR. Recordar que es necesario instalarlo previamente, ya que gImageaReader está basado en Tesseract OCR.
WINDOWS: Para descargarla, en el repositorio accederemos a la parte de Windows.
Y una vez dentro elegiremos el ejecutable para, en mi caso, 64 bits. Una vez ejecutado el instalador deberemos seleccionar nuestras preferencias, y cuando finalice, abriremos la aplicación, como otra cualquiera, para ver que todo funciona correctamente. Debe de aparecer la siguiente interfaz.
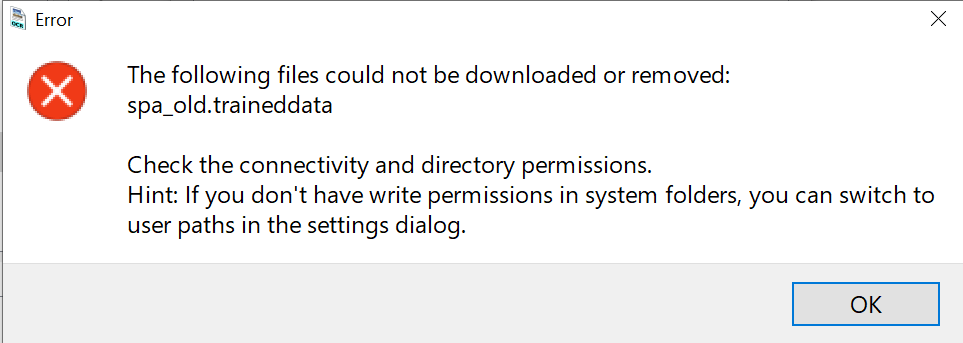
Por defecto, la aplicación viene preparada para reconocer texto en inglés. Si queremos cambiar los idiomas en que queremos que lo detecte, primeramente debemos de ejecutar la aplicación como administrador. En el caso de un uso normal, no será necesario. Si no ejecutamos la aplicación como administrador, nos aparecerá el siguiente error.
Si lo hemos iniciado como administrador, basta con pulsar el icono de una bandera azul con un desplegable y elegir la opción Manage Languages, y podremos elegir los idiomas con los que queremos trabajar. En mi caso, elegiré español también.
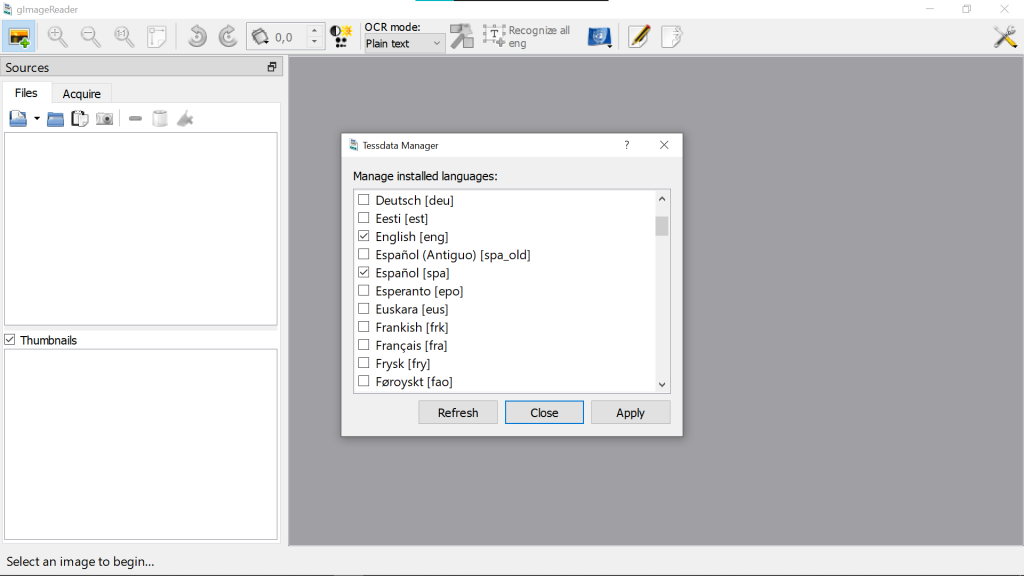
Al pulsar en Apply nos pedirá que instalemos este nuevo idioma y ya estará listo. Recordad que como esta aplicación depende de Tesseract OCR, según los idiomas que hayamos instalado en este, podremos instalarlos en gImageReader.
LINUX: Para una distribución de GNU/Linux como puede ser Ubuntu, en el repositorio. Deberemos de abrir una terminal y primeramente con el siguiente comando: sudo add-apt-repository ppa:sandromani/gimagereader podemos añadir el repositorio PPA de gImageReader. Seguidamente actualizaremos los paquetes con el comando sudo apt update y, seguidamente, con sudo apt upgrade. Ya por último, instalamos la propia aplicación con sudo apt install gimagereader. En mi caso personal, me apareció un error por incongruencia de versiones, por lo que tuve que hacer el siguiente comando previamente a instalar la aplicación: sudo apt install gimagereader-common=3.4.0-2.
Recordar que esta aplicación depende de que Tesseract OCR esté instalado en nuestro sistema.
Editar Contenido
Editar Texto
Para esta parte utilizaremos LibreOffice Draw. Para empezar, si queremos editar el texto ya escrito debemos hacer doble click sobre el cuadro de texto y podremos alterar su contenido. También se puede añadir un nuevo cuadro de texto, si así lo deseamos.
Cambiar de posición un bloque (imagen o cuadro de texto)
Para esta parte utilizaremos LibreOffice Draw y Scribus. Podemos ver que para cambiar de posición cualquier bloque basta con hacer click sobre el mismo y arrastrarlo a donde queramos. Es lo mismo tanto para imágenes como para cuadros de texto. Se presenta primero el ejemplo en LibreOffice Draw y posteriormente en Scribus.
Editar Páginas
Cambiar orden de las páginas
Para esta parte utilizaremos LibreOffice Draw y PDF Arranger. Para utilizar la primera herramienta, en la parte izquierda de la pantalla, donde nos aparece una previsualización de las propias páginas, podemos seleccionar la página que queramos mover y con el ratón arrastrarla a la posición que queramos.
Por otro lado, en el caso de PDF Arranger debemos de abrir el archivo a editar y, desde la interfaz que nos aparece, somos capaces de cambiar el orden de las páginas
Añadir o eliminar páginas (o PDFs enteros)
Para esta parte utilizaremos LibreOffice Draw y PDF Arranger. Para hacerlo con ambas herramientas, debemos de abrir los dos PDF que queramos unir, a la vez y en distintas pestañas, seleccionamos las páginas a copiar de uno a otro y simplemente arrastrando lo habremos copiado en el PDF de destino. De esta forma, si seleccionamos todas las páginas de un PDF, a efectos prácticos estamos uniendo PDFs. Desde este menú, también, se pueden eliminar páginas haciendo click derecho sobre la página y seleccionando la opción de eliminar página. Se presenta primero el ejemplo en LibreOffice Draw y posteriormente en PDF Arranger.
Bloquear PDFs
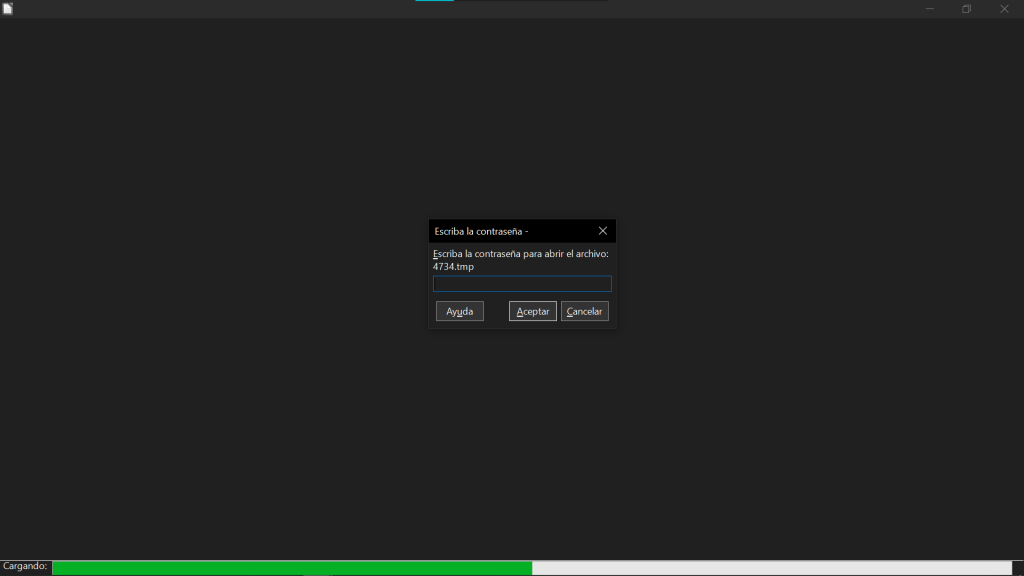
Para esta parte utilizaremos LibreOffice Draw. Hay veces donde queremos proteger nuestros archivos PDFs, ya que queremos que solo el que tenga clave de acceso pueda llegar a leerlo, o que cualquiera pueda leerlo, pero no tengan permiso de edición. Para ello, LibreOffice Draw nos permite, mediante una exportación más manual, poder elegir, entre otros parámetros, si queremos añadir una contraseña. Para ello, debemos acceder a Archivo -> Exportar a -> Exportar a PDF -> Seguridad -> Establecer contraseñas. A continuación se muestra cómo se haría.
Tal y como hemos visto, a parte de establecer una contraseña de permisos de acceso, podemos también establecer si permitimos impresión o no, si se puede editar, si se puede copiar contenido, etc. Una vez el destinatario reciba el archivo, antes de verse cualquier información deberá de acceder con la contraseña establecida.
Comprimir PDFs
Para esta parte utilizaremos LibreOffice Draw. En algunas ocasiones nos podemos encontrar limitados por un cierto tamaño máximo permitido de PDF. Para ello, podemos comprimir nuestro PDF y así haremos que ocupe menos. Dado que un PDF principalmente está relleno por caracteres de texto e imágenes, si reducimos el tamaño de estas últimas conseguiremos reducir también el tamaño de nuestro archivo final. Para ello, LibreOffice Draw, siguiendo la ruta del apartado anterior, nos permite configurar ciertos parámetros mediante los cuales conseguimos comprimir las imágenes. Para ello, debemos de acceder a Archivo -> Exportar a -> Exportar a PDF -> General -> Imágenes. En esta sección nos aparece para configurar, por ejemplo, el tipo de compresión que queremos hacer a las imágenes, o si queremos reducir la resolución. Una configuración adecuada puede ser una compresión JPEG a una calidad del 80%, junto a una resolución de imagen de 150PPP, donde reduciremos el tamaño del archivo, sin que los cambios apenas se aprecien. A continuación se muestra en vídeo cómo se haría.
Para mostrar datos numéricos, el tamaño de mi archivo inicial era de 1.46MB, y tras la compresión se ha reducido a 1.33MB. Quizá pueda parecer poco, pero el archivo de prueba contiene apenas un par de fotos.
OCR (Reconocimiento Óptico de Caracteres)
Tal y como se mencionó al principio, para esta parte podemos utilizar Tesseract OCR directamente desde la terminal (ver repositorio), o, con el anterior previamente instalado, con gImageReader lo podemos ejecutar con una interfaz gráfica. Para este último, una vez estemos dentro de la aplicación, deberemos de abrir la carpeta donde se encuentre la imagen o el PDF del cual vamos a extraer el texto. Una vez abierta la imagen podemos distribuirla por párrafos o no, y si pulsamos en el botón Recognize all automáticamente se generará el texto en el idioma elegido. Una vez hecho eso, podemos copiar el texto o exportarlo como un archivo .txt. A continuación se muestra un ejemplo de uso.
En este ejemplo se muestra desde cómo añadir o quitar idiomas que queremos que detecte, a cómo la aplicación nos detecta párrafos automáticamente y, cómo finalmente se extrae el texto y podemos tanto copiarlo directamente como exportarlo a un archivo .txt.
Una vez presentado cómo instalar y utilizar estos programas, es importante señalar que existen muchas otras herramientas para la edición de PDFs, pero en este tutorial nos hemos centrado en aquellas basadas en Software Libre.
Podéis contactarnos a través de la dirección de correo osl@ugr.es para cualquier duda que pueda surgir ¡Estaremos encantados de atenderos!




Deja una respuesta