Esto es un documento que recoge una introducción a Ollama, el proceso de instalación y su ejecución, tanto de forma local como mediante una interfaz gráfica, tal y como ofrecen los clientes de IA más reconocidos.
1. Introducción
Ollama es un cliente de modelos de inteligencia artificial, por lo que es la base sobre la que luego instalar un modelo en concreto como Deepseek, Mistral o Qwen. Ollama presenta dos particularidades principales:
- Permite usar una IA de forma local (instalado en tu propio ordenador), de modo que los datos se queden en el propio PC. Esto permite utilizar un modelo de IA sin conexión a internet y esquivar las censuras que un modelo tenga en una web.
- Funciona a través de la terminal de tu ordenador, haciendo que, mediante el uso de la consola tengas acceso al modelo requerido, pudiendo realizar consultas directamente.
1.1. Algunos ejemplos de modelos libres.
Dentro de Ollama, existe una amplia diversidad de modelos de IA. En nuestro caso, nuestro cometido es centrarnos en aquellos que son libres. Para que un modelo sea considerado libre, se deben cumplir una serie de criterios:
- Acceso a los pesos del modelo: Los pesos (parámetros que el modelo aprende durante el entrenamiento para hacer predicciones precisas) deben de estar disponibles para descarga sin restricciones. Esto permite que cualquier persona pueda ejecutarlo en su propio hardware sin depender de una API externa.
- Código fuente disponible: Esto permite que los desarrolladores inspeccionen, mejoren y adapten el modelo a su gusto.
- Debe de estar baja una licencia de Software Libre: Por ejemplo, MIT, Apache 2.0 o GLP.
- Sin restricciones de uso: No debe imponer reglas sobre cómo utilizarlo, permitiendo a los usuarios emplearlo para cualquier propósito.
Algunos modelos disponible en Ollama y que cumple estas características son:
- Deepseek-r1: Los pesos del modelo están licenciados bajo la Licencia MIT. La serie DeepSeek-r1 admite el uso comercial y permite cualquier modificación y trabajos derivados, incluyendo, entre otros, la destilación para entrenar otros modelos de lenguaje (LLMs).
- Phi4: Desarrollado por Microsoft, es un modelo abierto de última generación con 14 mil millones de parámetros, construido a partir de una combinación de conjuntos de datos sintéticos, datos de sitios web de dominio público filtrados y libros académicos adquiridos, junto con conjuntos de datos de preguntas y respuestas. Presenta licencia MIT con la que se concede permiso, de forma gratuita, a cualquier persona que obtenga una copia de este software y su documentación asociada para usarlo, copiarlo, modificarlo, fusionarlo, publicarlo, distribuirlo, sublicenciarlo y/o venderlo sin restricciones, siempre que se incluya el aviso de copyright y esta autorización en todas las copias o partes sustanciales del software.
- Mistral: Es un modelo con 7 mil millones de parámetros, distribuido bajo la licencia Apache. Está disponible en dos versiones: una para seguir instrucciones (instruct) y otra para completar texto.
- Qwen2.5: Incluye modelos base y modelos ajustados para seguir instrucciones, con tamaños que van desde 0.5 hasta 72 mil millones de parámetros. Todos los modelos, excepto los de 3B y 72B, se distribuyen bajo la licencia Apache 2.0. Los modelos de 3B y 72B están bajo la licencia Qwen.
2. Proceso de instalación
2.1. Requerimientos.
En términos de CPU, lo óptimo es optar por un procesador Intel de 11ª generación o uno basado en Zen4 de AMD. La razón principal es la compatibilidad con AVX512, una tecnología que acelera las operaciones de multiplicación de matrices utilizadas en modelos de inteligencia artificial. Más que la cantidad de núcleos, lo crucial es el conjunto de instrucciones soportado por la CPU. Además, los procesadores modernos con soporte para DDR5 ofrecen un mayor ancho de banda de memoria, lo que mejora el rendimiento al manejar modelos de IA.
En cuanto a memoria RAM, el mínimo recomendado es 16GB, suficiente para manejar modelos de 7 mil millones de parámetros (7B) con un desempeño aceptable. Esta cantidad permite trabajar con modelos más pequeños de forma fluida o con modelos más grandes con ciertas restricciones.
El mínimo práctico de disco duro o SSD es de 50GB, lo necesario para instalar el contenedor Docker (que ocupa aproximadamente 2GB en el caso de Open-WebUI) y los archivos del modelo. No es necesario un almacenamiento mucho mayor si solo se busca cubrir lo esencial.
La GPU no es obligatoria, pero es altamente recomendable. La capacidad de la GPU para ejecutar modelos cuantizados depende de la generación y cantidad de VRAM disponible.
Modelos en FP16 (no cuantizados): Un modelo 7B en FP16 requiere 26GB de VRAM, lo que excede la mayoría de las GPUs de consumo.
Modelos cuantizados (4-bit): Reducen la demanda de VRAM:
- 7B: ~4GB
- 13B: ~8GB
- 30B: ~16GB
- 65B: ~32GB
Para modelos mayores a 13B o MoE, se necesita hardware especializado, como Mac con chips optimizados o GPUs de alto rendimiento, ya que en equipos estándar resultan poco prácticos (https://github.com/open-webui/open-webui/discussions/736#discussioncomment-8474297).
2.2. Instalación.
- En Linux:
curl https://ollama.ai/install.sh | sh - En Windows: Se instala desde la web y se necesita Docker Desktop para la interfaz web.
- En MAC: En MacOS, se instala de manera equivalente a Windows.
La instalación se verifica con el comando ollama --version
2.3. Interfaz y entornos de ejecución.
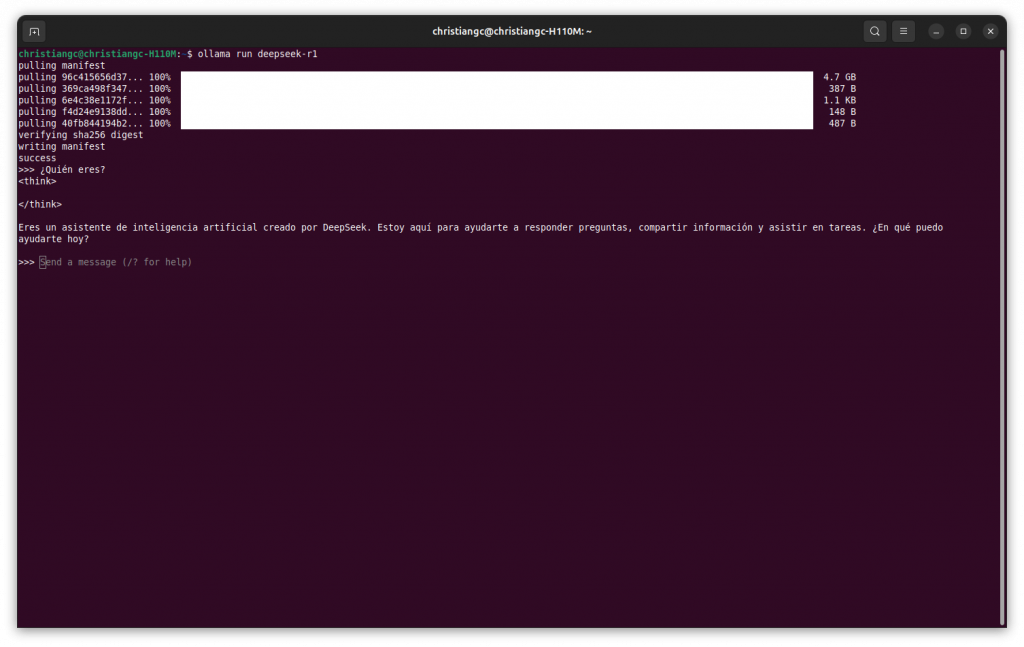
Para la ejecución de un modelo de Ollama, se hace, en primer lugar, ejecutando el comando ollama run <modelo> en una terminal (CLI). Esto nos permitirá tener un LLM de manera totalmente local, con las ventajas que ello supone. Por ejemplo, los datos no se envían a terceros, si no que se almacenan en nuestro propio PC.
Si, en cambio, queremos ejecutar nuestros modelos en una interfaz web, totalmente personalizable por nosotros, podemos utilizar Open WebUI.
, que permite una interacción gráfica con los LLMs. Para llevar a cabo esto, existen 2 opciones posibles: Docker o VirtualEnv.
Docker es una tecnología de contenedores que permite crear y ejecutar aplicaciones de forma modular y liviana, similar a máquinas virtuales pero más eficientes. Utiliza el kernel de Linux para aislar procesos, optimizando el uso de infraestructura sin comprometer la seguridad.
Sus principales ventajas incluyen:
- Flexibilidad para crear, copiar y trasladar contenedores entre entornos.
- Modelo de implementación basado en imágenes, facilitando la distribución con todas sus dependencias.
- Automatización del despliegue de aplicaciones en contenedores.
- Rapidez y control en implementaciones, con gestión eficiente de versiones.
Para ejecutar la interfaz web a partir de Docker, utilizaremos el siguiente comando:docker run -d -p 3000:8080 -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollama
Una vez hecho esto, debemos de cargar el modelo en Open WebUI. Para ello, en el buscador escribimos la dirección y el puerto donde opera Ollama, nos creamos una cuenta y, en el apartado de Configuración>Modelos>Obtener un modelo de Ollama, ingresamos la etiqueta del modelo que deseamos descargar.
Con esto, tendremos nuestro propio LLM, tanto ejecutable desde la terminal como desde la interfaz web de Open WebUI.
Una manera que puede resultar más útil y sencilla para ejecutar nuestros modelos en la interfaz web Open WebUI es abrirlo en un entorno virtual de Python.
⚠️ Importante:
Con la versión 3.12, se obtienen errores, por lo que se debe instalar una versión anterior. Para ello, se debe añadir un repositorio mediante el siguiente comando:
sudo add-apt-repository ppa:deadsnakes/ppa
Una vez hecho esto, ya podemos instalarlo: sudo apt install python3.11-venv y crear nuestro entorno virtual a través del comando: python3.11 -m venv ollama-webui
Posteriormente, activamos el entorno: . ./ollama-webui/bin/activate y, finalmente, abrimos el servidor: open-webui serve
Finalmente, podemos acceder mediante la interfaz web a nuestros modelos de Ollama, a través de la dirección: localhost:8080.
3. Personalización y entrenamiento.
Otro aspecto interesante de Ollama es que podemos modificar el comportamiento de nuestro LLM. Para ello, creamos un archivo de texto donde indicamos el modelo del que queremos que derive: FROM . En dicho archivo, se deben indicar los siguientes parámetros:
- Temperature: Comprende valores entre 0 y 1. Cuanto más cercano a 1, su comportamiento y respuestas serán más creativas, mientras que cuanto más bajo sea, el modelo será más coherente.
- SYSTEM: Entre “”” “”” indicamos cómo queremos que se comporte el modelo, p.e. indicarle que se comporte como un personaje de Super Mario Bros.
- top_p y top_k controlan la creatividad y la aleatoriedad del modelo.
4. Ventajas de usar LLMs libres.
Los modelos de lenguaje de gran tamaño (LLMs, por sus siglas en inglés) de código abierto ofrecen múltiples ventajas para empresas, desarrolladores y usuarios en general. A continuación, se presentan algunas de las más importantes:
- Transparencia y Seguridad
- Código abierto y auditable: Se pueden inspeccionar para detectar sesgos, errores o vulnerabilidades de seguridad.
- Control total: No dependen de servidores externos, lo que evita la recopilación de datos no deseada.
- Personalización y Flexibilidad
- Adaptables a necesidades específicas: Se pueden entrenar y ajustar para tareas concretas o dominios específicos.
- Modificación y optimización: Permiten ajustar parámetros para mejorar el rendimiento en hardware específico.
- Independencia y Autonomía
- Sin dependencia de terceros: No estás atado a empresas privadas que pueden cambiar términos de uso o limitar el acceso.
- Acceso offline: Algunos modelos pueden ejecutarse localmente sin necesidad de conexión a internet.
- Costo y Escalabilidad
- Reducción de costos: Evitan tarifas de uso de APIs comerciales.
- Escalabilidad sin restricciones comerciales: Pueden desplegarse en infraestructura propia sin límites de uso impuestos por proveedores.
- Comunidad y Colaboración
- Mejoras continuas: La comunidad contribuye con optimizaciones, reduciendo tiempos de desarrollo.
- Compatibilidad con múltiples herramientas: Se integran fácilmente con frameworks de IA populares como Hugging Face, TensorFlow o PyTorch.





Deja una respuesta